
The Free Lunch Is Over
O The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software, numa tradução livre “O Almoço Grátis Acabou: Uma Virada Fundamental em Direção à Concorrência em Software”, é um artigo de 2005 alertando sobre a concorrência e multithreading, e será descrito brevemente a seguir.

Andy and Bill’s law
A lei de Andy e Bill é uma afirmação de que o novo software sempre consumirá qualquer aumento no poder computacional que o novo hardware possa fornecer. A lei se origina de uma frase humorística contada na década de 1990 durante conferências de computação:
“what Andy giveth, Bill taketh away.”
A frase é uma brincadeira com as estratégias de negócios do ex-CEO da Intel (hardware), Andy Grove, e do ex-CEO da Microsoft (software), Bill Gates.
The Free Performance Lunch
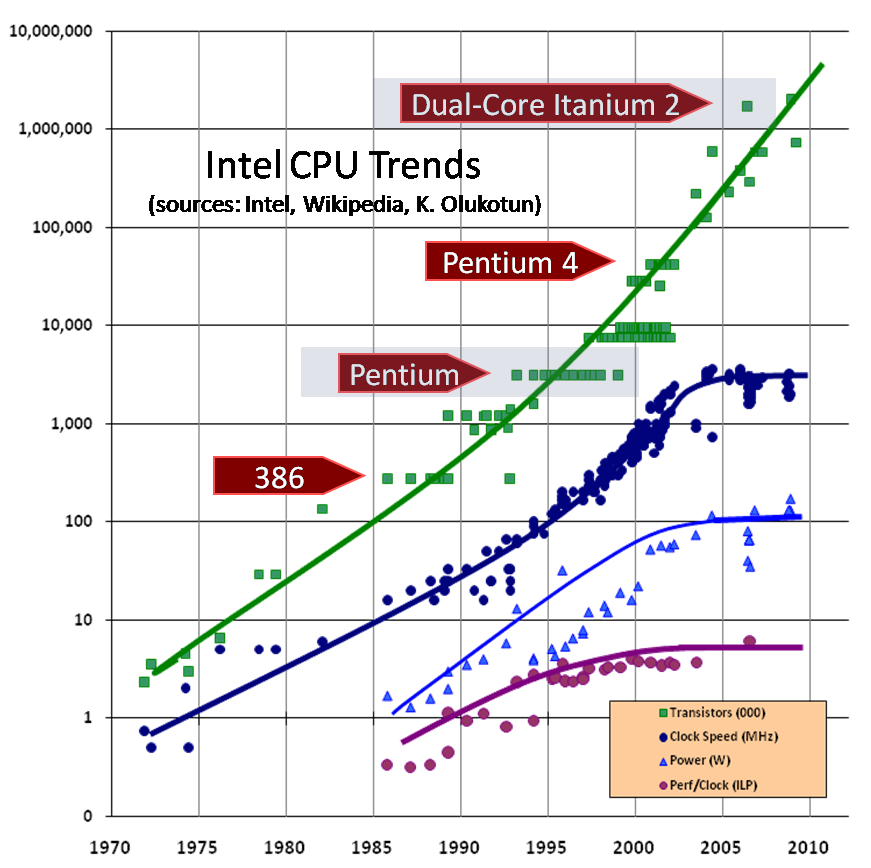
Não importa o quão rápido os processadores se tornem, o software sempre encontra novas maneiras de consumir a velocidade extra. Faça uma CPU dez vezes mais rápida e o software normalmente encontrará dez vezes mais coisas para fazer (ou, em alguns casos, sentir-se à vontade para fazê-lo com dez vezes menos eficiência). A maioria das classes de aplicativos tem desfrutado de ganhos de desempenho gratuitos e regulares por várias décadas, mesmo sem lançar novas versões ou fazer nada de especial, porque os fabricantes de CPU (principalmente) e os fabricantes de memória e disco (secundariamente) habilitaram de forma confiável sistemas cada vez mais novos e cada vez mais rápidos. A velocidade do clock não é a única medida de desempenho, ou mesmo necessariamente uma boa, mas é instrutiva: estamos acostumados a ver CPUs de 500 MHz darem lugar a CPUs de 1 GHz, dando lugar a CPUs de 2 GHz e assim por diante. Hoje estamos na faixa de 3 GHz em computadores convencionais.
A questão chave é: quando isso vai acabar? Afinal de contas, a Lei de Moore prevê o crescimento exponencial, e é evidente que o crescimento exponencial não pode continuar para sempre antes de atingirmos limites físicos… A luz não está ficando mais rápida. O crescimento deverá eventualmente desacelerar e até mesmo terminar.
Advertência: Sim, a Lei de Moore se aplica principalmente às densidades de transistores, mas o mesmo tipo de crescimento exponencial ocorreu em áreas relacionadas, como velocidades de clock. Há um crescimento ainda mais rápido em outros espaços, mais notavelmente a explosão de armazenamento de dados, mas essa tendência importante pertence em um artigo diferente.
Se você é um desenvolvedor de software, é provável que já esteja aproveitando a onda do “almoço grátis” do desempenho de computadores desktop. O desempenho da sua aplicação está no limite para algumas operações locais? “Não se preocupe”, diz a sabedoria convencional; “Os processadores de amanhã terão ainda mais rendimento e, de qualquer forma, os aplicativos de hoje são cada vez mais limitados por outros fatores além do rendimento da CPU e da velocidade da memória (por exemplo, eles são frequentemente vinculados a E/S, vinculados à rede, vinculados ao banco de dados).” Certo?
Certo, no passado. Mas completamente errado no futuro próximo.
A boa notícia é que os processadores continuarão a se tornar mais poderosos. A má notícia é que, pelo menos no curto prazo, o crescimento ocorrerá principalmente em direções que não comportam a maioria dos aplicativos atuais em seu habitual passeio gratuito.
Clock Speed
Por volta do início de 2003, você notará uma preocupante mudança brusca na tendência anterior de velocidades de clock da CPU cada vez mais rápidas. Adicionei linhas para mostrar as tendências de limite na velocidade máxima do clock; em vez de continuar no caminho anterior, conforme indicado pela linha pontilhada fina, há um achatamento acentuado. Tem se tornado cada vez mais difícil explorar velocidades de clock mais altas devido a não apenas um, mas vários problemas físicos, principalmente o calor (muito grande e difícil de dissipar), o consumo de energia (muito alto) e problemas de vazamento de corrente.

Fonte: http://www.gotw.ca/images/CPU.png
{kind=link}
2 x 3GHz < 6 GHz?
Portanto, uma CPU dual-core que combina dois núcleos de 3GHz oferece praticamente 6GHz de capacidade de processamento. Certo?
Errado. O fato de ter dois threads em execução em dois processadores físicos não significa que o desempenho seja duas vezes maior. Da mesma forma, a maioria dos aplicativos com vários threads não será executada duas vezes mais rápido em um equipamento dual-core. Eles devem ser executados mais rapidamente do que em uma CPU de núcleo único; o ganho de desempenho não é linear.
Por quê não? Em primeiro lugar, há uma sobrecarga de coordenação entre os núcleos para garantir a coerência do cache (uma visão consistente do cache e da memória principal) e para realizar outros handshaking. Atualmente, uma máquina com dois ou quatro processadores não é realmente duas ou quatro vezes mais rápida do que uma única CPU, mesmo para aplicativos multithread. O problema permanece essencialmente o mesmo, mesmo quando as CPUs em questão estão no mesmo molde.
Em segundo lugar, a menos que os dois núcleos estejam executando processos diferentes, ou diferentes threads de um único processo, que são bem escritos para serem executados independentemente e quase nunca esperam um pelo outro, eles não serão bem utilizados.
Se você estiver executando um aplicativo de thread único, ele só poderá usar um núcleo. Deve haver um aumento de velocidade, pois o sistema operacional e o aplicativo podem ser executados em núcleos separados, mas, normalmente, o sistema operacional não vai utilizar a CPU ao máximo, de modo que um dos núcleos ficará ocioso na maior parte do tempo.
O que isso significa para o software: A próxima revolução
Na década de 1990, aprendemos a entender os objetos. A revolução no desenvolvimento de software convencional, da programação estruturada para a programação orientada a objetos, foi a maior mudança desse tipo nos últimos 20 anos e, sem dúvida, nos últimos 30 anos. Houve outras mudanças, inclusive o renascimento mais recente (e genuinamente interessante) dos serviços da Web, mas nada que a maioria de nós tenha visto durante nossas carreiras foi uma mudança tão fundamental e de tão grande alcance na forma como escrevemos software quanto a revolução dos objetos.
Até agora.
A partir de hoje, o almoço de desempenho não será mais gratuito. É claro que continuarão a existir ganhos de desempenho geralmente aplicáveis que todos podem obter, principalmente graças às melhorias no tamanho do cache. Mas se você quiser que seu aplicativo se beneficie dos avanços exponenciais contínuos na taxa de transferência dos novos processadores, ele precisará ser um aplicativo concorrente (geralmente multithread) bem escrito. E é mais fácil falar do que fazer, porque nem todos os problemas são inerentemente paralelizáveis e porque a programação concorrente é difícil.
Já estou ouvindo os protestos: “Concorrência? Isso não é novidade! As pessoas já estão escrevendo aplicativos concorrentes”. Isso é verdade. Para uma pequena fração de desenvolvedores. Lembre-se de que as pessoas têm feito programação orientada a objetos (OOP) pelo menos desde os dias do Simula, no final da década de 1960. Mas a OOP não se tornou uma revolução e dominante na corrente principal até a década de 1990. Por que então? A razão pela qual a revolução aconteceu foi principalmente o fato de nosso setor ter sido impulsionado por requisitos para escrever sistemas cada vez maiores que resolvessem problemas cada vez maiores e explorassem os recursos cada vez maiores de CPU e armazenamento que estavam se tornando disponíveis. Os pontos fortes da OOP em termos de abstração e gerenciamento de dependências a tornaram uma necessidade para obter um desenvolvimento de software em larga escala que fosse econômico, confiável e repetível.
Da mesma forma, temos programado de forma concorrente desde a idade das trevas, escrevendo corrotinas, monitores e outras coisas interessantes. E na última década, mais ou menos, temos visto cada vez mais programadores escrevendo sistemas concorrentes (multithread, multiprocessos). Mas uma verdadeira revolução marcada por uma grande virada em direção à concorrência demorou a se concretizar. Atualmente, a grande maioria dos aplicativos é de thread único, por ddiversas razões.
Conclusão
Caso ainda não tenha feito isso, agora é o momento de analisar com atenção o design do seu aplicativo, determinar quais operações são sensíveis à CPU no momento ou provavelmente se tornarão sensíveis em breve e identificar como esses locais podem se beneficiar da concorrência.
Agora também é o momento de você e sua equipe entenderem os requisitos, as armadilhas, os estilos e as expressões idiomáticas da programação concorrente.
Algumas raras classes de aplicativos são naturalmente paralelizáveis, mas a maioria não é. Mesmo quando você sabe exatamente onde está com problemas de CPU, pode ser difícil descobrir como paralelizar essas operações; mais uma razão para começar a pensar nisso agora. Os compiladores de paralelização implícita podem ajudar um pouco, mas não espere muito; eles não podem fazer um trabalho tão bom de paralelização do seu programa sequencial quanto o que você poderia fazer ao transformá-lo em uma versão explicitamente paralela e com threads.
Graças ao crescimento contínuo do cache e, provavelmente, a mais algumas otimizações incrementais de fluxo de controle em linha reta, o almoço grátis continuará por mais algum tempo; mas, a partir de hoje, o bufê servirá apenas aquela entrada e aquela sobremesa.
O filé mignon dos ganhos de throughput ainda está no cardápio, mas agora tem um custo extra - esforço extra de desenvolvimento, complexidade extra de código e esforço extra de teste. A boa notícia é que, para muitas classes de aplicativos, o esforço extra valerá a pena, pois a concorrência permitirá que eles explorem totalmente os ganhos exponenciais contínuos na taxa de transferência do processador.
Thread vs Process
Threads não são independentes uns dos outros, ao contrário dos processos. Como resultado, os threads compartilham com outros threads sua seção de código, seção de dados e recursos do sistema operacional, como arquivos abertos e sinais. Mas, assim como os processos, um thread possui seu próprio contador de programa (PC), um conjunto de registradores e um espaço de pilha.
Por quê multithreading? Threads são uma forma popular de melhorar a aplicação por meio do paralelismo. Por exemplo, em um navegador, várias guias podem ser threads diferentes. O MS Word usa vários threads, um thread para formatar o texto, outro thread para processar entradas, etc.
Threads operam mais rápido que processos devido aos seguintes motivos:
A criação de threads é muito mais rápida;
A alternância de contexto entre threads é muito mais rápida;
Threads podem ser encerrados facilmente;
A comunicação entre threads é mais rápida.
Concorrência vs Paralelismo
A concorrência diz respeito a várias tarefas que são iniciadas, executadas e concluídas em períodos de tempo sobrepostos, sem uma ordem específica. O paralelismo diz respeito a várias tarefas ou subtarefas da mesma tarefa que são executadas literalmente ao mesmo tempo em um hardware com vários recursos de computação, como um processador de vários núcleos. Como você pode ver, concorrência e paralelismo são semelhantes, mas não idênticos.
Concorrência
Programação como a composição de processos de execução independente.
A concorrência é uma propriedade semântica de um programa ou sistema. Concorrência é quando várias tarefas estão em andamento por períodos de tempo sobrepostos. Observe que aqui não estamos falando sobre a execução real das tarefas, mas sobre o projeto do sistema - que as tarefas são independentes da ordem. Portanto, a concorrência é uma propriedade conceitual de um programa ou de um sistema, e tem mais a ver com a forma como o programa ou o sistema foi projetado.
Imagine que um cozinheiro esteja cortando salada e, de vez em quando, mexendo a sopa no fogão. Ele precisa parar de cortar, verificar o fogão e, em seguida, começar a cortar novamente, repetindo esse processo até que tudo esteja pronto.
Como você pode ver, temos apenas um recurso de processamento aqui, o cozinheiro, e sua concorrência está relacionada principalmente à logística; sem concorrência, o cozinheiro tem de esperar até que a sopa no fogão esteja pronta para cortar a salada.
 Fonte: Concurrency vs Parallelism
Fonte: Concurrency vs Parallelism
Paralelismo
Programação como a execução simultânea de cálculos (possivelmente relacionados).
O paralelismo é uma propriedade de implementação. O paralelismo é literalmente a execução física simultânea de tarefas em tempo de execução e requer hardware com vários recursos de computação. Ele reside na camada de hardware.
De volta à cozinha, agora temos dois chefs, um que pode mexer e outro que pode cortar a salada. Dividimos o trabalho com outro recurso de processamento, outro chef.
O paralelismo é uma subclasse da concorrência: antes de poder realizar várias tarefas ao mesmo tempo, é preciso gerenciar várias tarefas primeiro.
 Fonte: Concurrency vs Parallelism
Fonte: Concurrency vs Parallelism
Conclusão
A essência da relação entre concorrência e paralelismo é que os cálculos simultâneos podem ser paralelizados sem alterar a precisão do resultado, mas a concorrência em si não implica em paralelismo. Além disso, o paralelismo não implica concorrência; muitas vezes é possível para um otimizador pegar programas sem concorrência semântica e dividi-los em componentes paralelos por meio de técnicas como processamento de pipeline, operações SIMD de vetor amplo ou dividir e conquistar.
Como Rob Pike apontou: “Concorrência é lidar com muitas coisas ao mesmo tempo. Paralelismo é fazer muitas coisas ao mesmo tempo”. Em uma CPU de núcleo único, é possível ter concorrência, mas não paralelismo. Mas ambos vão além do modelo sequencial tradicional, no qual as coisas acontecem uma de cada vez.
Para ter uma ideia melhor sobre a distinção entre concorrência e paralelismo, considere os seguintes pontos:
- Um aplicativo pode ser concorrente, mas não paralelo, o que significa que ele processa mais de uma tarefa ao mesmo tempo, mas não há duas tarefas sendo executadas no mesmo instante;
- Um aplicativo pode ser paralelo, mas não concorrente, o que significa que ele processa várias subtarefas de uma única tarefa ao mesmo tempo;
- Um aplicativo não pode ser paralelo nem concorrente, o que significa que ele processa uma tarefa por vez, sequencialmente, e a tarefa nunca é dividida em subtarefas;
- Um aplicativo pode ser paralelo e concorrente, o que significa que ele processa várias tarefas ou subtarefas de uma única tarefa ao mesmo tempo (executando-as em paralelo).
Não quero ser esse tipo de pessoa, mas a terminologia é importante. Com muita frequência, a conversa sobre o problema fica confusa porque uma pessoa pensa em concorrência e a outra pensa em paralelismo. Na prática, a distinção entre concorrência e paralelismo não é absoluta. Muitos programas têm aspectos de cada um deles.
Imagine que você tenha um programa que insere valores em uma tabela de hash. Se você distribuir a operação de inserção entre vários núcleos, isso é paralelismo. Mas coordenar o acesso à tabela de hash é concorrência.
Concorrência (Concurrency) no C++
Talvez a forma menos ameaçadora de multithreading seja a concorrência. A concorrência é geralmente entendida como a execução de várias threads ao mesmo tempo, mas sem partilhar quaisquer recursos. Isto significa que nenhuma estrutura de dados, memória ou outro é partilhado entre threads. A simultaneidade é normalmente utilizada para tarefas que podem ser divididas entre threads e trabalhadas de forma independente.
Para ilustrar isto, vejamos o exemplo de cada thread que recebe um ponteiro para um número inteiro, incrementa esse número inteiro e depois pára. Cada thread pode ser executada até incrementar o número algumas centenas de vezes. Depois, essas threads, muitas vezes chamadas de threads de “trabalho”, juntam-se à thread principal. Todas as threads trabalham simultaneamente.
https://onlinegdb.com/TbSvhsU2C
#include <thread>
#include <iostream>
void workFunc(int* ptr, size_t times)
{
while(times--) {
*ptr += 1;
}
}
int main(int argc, char const *argv[])
{
int* numbers = new int[3];
std::thread t1(workFunc, numbers, 500);
std::thread t2(workFunc, numbers + 1, 600);
std::thread t3(workFunc, numbers + 2, 700);
t1.join();
t2.join();
t3.join();
for(int i = 0; i < 3; ++i)
std::cout << "Number Slot " << (int)i << " is " << (int)numbers[i] << std::endl;
delete[] numbers;
return 0;
}
Result:
Number Slot 0 is 500
Number Slot 1 is 600
Number Slot 2 is 700
Join
Se é novo no multithreading, há algumas partes deste código que podem não fazer sentido. O método join() é provavelmente uma delas. Um detalhe importante a entender sobre o início de novas threads é que elas trabalham e funcionam totalmente separadas da thread principal, a thread que começa em main() . Como elas são totalmente separadas, temos que decidir um ponto no qual queremos esperar que elas completem o trabalho que lhes foi atribuído.
Pense em join() de forma semelhante a como duas pessoas podem se separar para fazer suas próprias tarefas separadas, e então “se juntar” novamente mais tarde. Se você estiver viajando ou indo a algum lugar com um amigo, você não quer simplesmente abandoná-lo! O ideal é esperar que ele se junte a nós novamente. A mesma lógica se aplica às threads. Sempre que são criadas threads adicionais, há a obrigação de indicar como se pretende que a thread central e principal atue.
Detach
Você sempre precisa usar join nas threads? Não. Na verdade, há uma outra opção. Assim como no exemplo dos amigos, é possível que um amigo queira seguir seu próprio caminho de volta para casa e não se encontrar com você. No caso das threads, isso é chamado de detaching. Separar um thread significa permitir que ele trabalhe e conclua seu trabalho independentemente da thread principal. Porém, isso pode ser perigoso. Veja o exemplo a seguir, muito semelhante ao de join() , por exemplo.
/******************************************************************************
Online C++ Compiler.
Code, Compile, Run and Debug C++ program online.
Write your code in this editor and press "Run" button to compile and execute it.
*******************************************************************************/
#include <thread>
#include <iostream>
#include <cstring>
#include <regex>
#include <algorithm>
void workFunc(int* ptr, size_t times)
{
while(times--) {
*ptr += 1;
}
}
int main(int argc, char const *argv[])
{
int* numbers = new int[3];
std::thread t1(workFunc, numbers, 50000);
std::thread t2(workFunc, numbers + 1, 60000);
std::thread t3(workFunc, numbers + 2, 70000);
t1.detach();
t2.detach();
t3.detach();
delete[] numbers;
return 0;
}
O primeiro risco aqui é usar o heap alocado depois de ter sido excluído. Ao contrário de join() , detach() não faz com que a thread de chamada pare ou espere por nada. Isso significa que, assim que a terceira chamada para detach() terminar, a thread de chamada excluirá a matriz de números. Se as threads criadas não tiverem concluído seu trabalho, eles estarão gravando em uma matriz excluída, o que corrompe a memória.
O segundo risco aqui é que os threads criados podem continuar em execução mesmo após o término do thread principal, se o trabalho deles não for concluído. Ou eles podem ser eliminados assim que o principal terminar. Esse é um comportamento indefinido (undefined behavior) de acordo com o padrão C++. Independentemente do que um compilador específico possa garantir, o comportamento indefinido é algo que deve ser evitado. Há casos de uso válidos para detach(), mas qualquer um deles exige alguma outra forma de sincronização entre threads para ser confiável.
Thread Management
Cada programa em execução tem pelo menos uma thread que é ocupada por seu ponto de entrada. Pode haver muitas threads em um único programa e a memória é compartilhada entre todos os threads. Os objetos possuídos pelo thread principal (e compartilhados por outros threads como referência a ele) seriam destruídos assim que saíssem do escopo. Isso pode levar ao acesso corrupto à memória pelos demais threads.
Por isso, às vezes, é muito importante garantir que todos os threads sejam unidos usando std::thread::join() antes do término do thread principal. Outras vezes, você basicamente quer que um thread daemon seja executado em segundo plano, mesmo após o término do thread principal, e isso pode ser conseguido chamando std::thread::detach(), mas pode ou não ser possível unir um thread detached.
A RAII (Resource Acquisition Is Initialization, Aquisição de recursos é inicialização) é um famoso padrão de programação em C++ (na verdade, um termo errôneo), também conhecido e compreendido como Gerenciamento de recursos vinculado ao escopo (Scope-Bound Resource Management). Em C++, assim que o objeto é declarado (*), o método construtor da classe é evocado, o que geralmente é responsável pela alocação de recursos. Da mesma forma, quando o objeto sai do escopo, o destrutor é chamado, o que geralmente é responsável por liberar os recursos adquiridos.
A RAII é uma boa maneira de garantir que um thread seja unido, escrevendo uma classe de wrapper como um contêiner para a instância do thread que chama a união em seu destrutor. Os funtores são usados de forma semelhante para envolver as funções, sobrecarregando o operador de chamada () que torna uma classe chamável.
O C++ tem uma biblioteca robusta para dar suporte ao gerenciamento de threads. Uma instância de thread pode receber qualquer chamável (funções, functors, binds ou funções lambda) e seus parâmetros como argumentos. É importante observar que os parâmetros chamam o construtor de cópia padrão para criar uma cópia do parâmetro em seu escopo. Portanto, para realmente “compartilhar” a memória entre o thread chamador e o thread receptor, os objetos de parâmetro devem ser envolvidos com std::ref() ou pela maneira convencional de chamar usando ponteiros. Para transferir a propriedade de um objeto, o objeto pode ser envolvido com std::move(), que evoca o construtor move em vez do construtor copy no momento da inicialização.
Shared Resources
Um recurso em que dois threads diferentes podem acessar o mesmo endereço de memória é chamado de recurso compartilhado. É fundamental observar a ênfase no endereço. No exemplo anterior mostrado aqui, com vários threads acessando o mesmo array, esse não é um recurso compartilhado porque nenhum dos dois threads está lendo ou gravando no mesmo endereço de memória. A matriz poderia ter sido apenas quatro ponteiros inteiros separados; não há nada em uma matriz que a torne um recurso compartilhado.
Ao contrário da concorrência, um recurso compartilhado é usado quando é desejável que os threads executem trabalhos nos mesmos dados ou objetos. Isso significa que os objetos não são alocados na própria pilha de um thread, e apenas um é visível para outros threads. O que pode tornar isso difícil de entender é que, embora ambos os threads possam acessar algum recurso, eles nunca podem ver os outros threads acessando esse recurso.
Um ótimo exemplo de um recurso compartilhado na vida real é uma pista de pouso de um aeroporto à noite. Uma pista tem luzes piscantes para ajudar os aviões a se alinharem com ela enquanto se preparam para o pouso. Mas é muito difícil, se não impossível, que os outros aviões se vejam à noite, devido à escuridão e à velocidade com que se deslocam. Se um avião tentasse aterrissar na pista ao mesmo tempo que outro avião, seria desastroso. A única maneira de os aviões evitarem essas colisões é se coordenarem por meio do controle de tráfego aéreo.
Os threads funcionam da mesma forma, no sentido de que dependem de mecanismos de sincronização para coordenar o acesso aos recursos, como, por exemplo, não gravar neles exatamente ao mesmo tempo. O mecanismo que discutiremos aqui, que talvez seja o mais comum, é um mutex. Um mutex, conhecido pelo tipo std::mutex, permite que os threads adquiram bloqueios. Os bloqueios são uma forma de controle que permite que apenas um thread prossiga em uma seção de código por vez.
Vejamos este exemplo.
#include <thread>
#include <mutex>
#include <queue>
template<class T>
class SafeQueue {
public:
void push(const T& val) {
std::lock_guard<std::mutex> lock(_m);
_q.push(val);
}
bool pop(T& val) {
std::lock_guard<std::mutex> lock(_m);
if (!_q.empty()) {
val = _q.front();
_q.pop();
return true;
} else {
return false;
}
}
private:
std::mutex _m;
std::queue<T> _q;
};
No exemplo acima, os métodos push() e pop() da classe acontecem enquanto o thread de chamada constrói um bloqueio no mutex associado à fila. Esse bloqueio é melhor usado como um objeto de estilo RAII, onde está ativo apenas em algum escopo de código. Assim que o programa termina esse escopo, o objeto lock guard é destruído, permitindo que outro thread construa e adquira um bloqueio no mutex. Esse padrão continua a satisfazer a condição de que apenas um thread pode modificar a fila por vez.
Mutexes ainda são potencialmente perigosos
Embora pareçam muito legais e diretos, os mutexes ainda podem ser perigosos. Quando um thread adquire um bloqueio em um mutex, ele é responsável por liberar ou destruir esse bloqueio para que outros threads também possam acessar o escopo seguro do código. O que acontece se um thread nunca libera o bloqueio que adquiriu? Bem, algo muito ruim.
Um deadlock ocorre quando um thread bloqueia um mutex, mas esse bloqueio, por algum motivo, nunca pode ser desbloqueado. Se isso acontecer, todos os threads ficarão bloqueados e aguardarão o mutex indefinidamente, sem fazer nenhum progresso ou trabalho.
A regra geral para os mutexes é pensar com cuidado e criticamente sobre o que um thread faz quando coloca um bloqueio em um mutex. É fundamental que um thread só bloqueie quando for absolutamente necessário o acesso de um único thread e, ao fazê-lo, trabalhe o mais rápido possível. Embora os mutexes forneçam um meio de acessar com segurança o mesmo recurso, eles o fazem com um custo de desempenho.
Lock Guard
Com o seguinte código:
#include <iostream>
#include <thread>
#include <list>
#include <algorithm>
#include <mutex>
using namespace std;
// a global variable
std::list<int>myList;
// a global instance of std::mutex to protect global variable
std::mutex myMutex;
void addToList(int max, int interval)
{
// the access to this function is mutually exclusive
std::lock_guard<std::mutex> guard(myMutex);
for (int i = 0; i < max; i++) {
if( (i % interval) == 0) myList.push_back(i);
}
}
void printList()
{
// the access to this function is mutually exclusive
std::lock_guard<std::mutex> guard(myMutex);
for (auto itr = myList.begin(), end_itr = myList.end(); itr != end_itr; ++itr ) {
cout << *itr << ",";
}
}
int main()
{
int max = 100;
std::thread t1(addToList, max, 1);
std::thread t2(addToList, max, 10);
std::thread t3(printList);
t1.join();
t2.join();
t3.join();
return 0;
}
Observando a linha:
std::lock_guard<std::mutex> guard(myMutex);
Observe que o lock_guard faz referência ao mutex global myMutex. Ou seja, o mesmo mutex para todos os três threads. O que o lock_guard faz é basicamente isso:
Ao ser construído, ele bloqueia o myMutex e mantém uma referência a ele.
pós a destruição (ou seja, quando o escopo do guard é deixado), ele desbloqueia o myMutex.
O mutex é sempre o mesmo, não tem nada a ver com o escopo. O objetivo do lock_guard é apenas facilitar o bloqueio e o desbloqueio do mutex para você. Por exemplo, se você bloquear/desbloquear manualmente, mas sua função lançar uma exceção em algum lugar no meio, ela nunca chegará à instrução de desbloqueio.
Portanto, ao fazer isso manualmente, você precisa ter certeza de que o mutex está sempre desbloqueado. Por outro lado, o objeto lock_guard é destruído automaticamente sempre que a função é encerrada, independentemente de como ela é encerrada.
Isso evita ter que fazer unlock em todas as exceções e sempre realizar um try/catch para evitar o dead lock em caso de exceções.
Sincronização
Deadlock vs Starvation
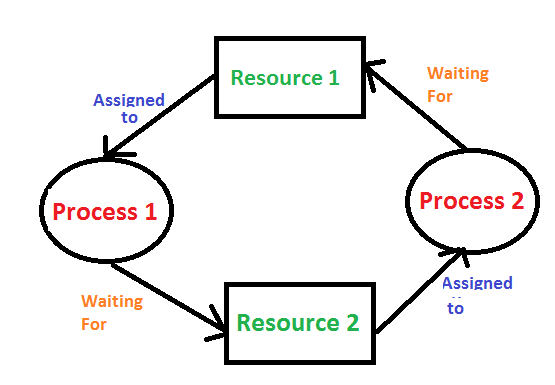
O deadlock ocorre quando cada processo mantém um recurso e espera por outro recurso detido por qualquer outro processo. As condições necessárias para que o deadlock ocorra são Exclusão mútua, Manter e esperar, Sem preempção e Espera circular. Nesse caso, nenhum processo que detenha um recurso e esteja esperando por outro é executado. Por exemplo, no diagrama abaixo, o processo 1 está mantendo o recurso 1 e aguardando o recurso 2, que é adquirido pelo processo 2, e o processo 2 está aguardando o recurso 1. Portanto, tanto o processo 1 quanto o processo 2 estão em deadlock.
Fonte: GeeksForGeeks
Starvation é o problema que ocorre quando os processos de alta prioridade continuam sendo executados e os processos de baixa prioridade ficam bloqueados por tempo indefinido. Em um sistema de computador muito carregado, um fluxo constante de processos de prioridade mais alta pode impedir que um processo de baixa prioridade obtenha a CPU. No starvation, os recursos são continuamente utilizados por processos de alta prioridade. O problema da starvation pode ser resolvido com o uso do Aging. No Aging, a prioridade dos processos que estão esperando há muito tempo é aumentada gradualmente.
| S.NO | Deadlock | Starvation |
|---|---|---|
| 1. | Todos os processos ficam aguardando a conclusão uns dos outros e nenhum é executado | Os processos de alta prioridade continuam sendo executados e os processos de baixa prioridade são bloqueados |
| 2. | Os recursos são bloqueados pelos processos | Os recursos são utilizados continuamente pelos processos de alta prioridade |
| 3. | Condições necessárias: Exclusão Mútua, Manter e Esperar, Sem Preempção, Espera Circular | As prioridades são atribuídas aos processos |
| 4. | Também conhecido como espera circular | Também conhecido como trava viva |
| 5. | Pode ser prevenido evitando-se as condições necessárias para o deadlock | Pode ser evitado pelo Aging |
Seção Crítica
Na ciência da computação, uma seção crítica (Critical Section) refere-se a um segmento de código que é executado por vários threads concorrentes ou processos simultâneos e que acessa recursos compartilhados. Esses recursos podem incluir memória compartilhada, arquivos ou outros recursos do sistema que só podem ser acessados por um thread ou processo por vez para evitar inconsistência de dados ou condições de corrida.
A seção crítica deve ser executada como uma operação atômica, o que significa que uma vez que um thread ou processo tenha entrado na seção crítica, todos os outros threads ou processos devem esperar até que o thread ou processo em execução saia da seção crítica. O objetivo dos mecanismos de sincronização é garantir que apenas um thread ou processo possa executar a seção crítica por vez.
O conceito de seção crítica é central para a sincronização em sistemas de computador, pois é necessário garantir que vários threads ou processos possam ser executados simultaneamente sem interferir uns nos outros. Vários mecanismos de sincronização, como semáforos, mutexes, monitores e variáveis de condição, são usados para implementar seções críticas e garantir que os recursos compartilhados sejam acessados de maneira mutuamente exclusiva.
A utilização de seções críticas na sincronização pode ser vantajosa para melhorar o desempenho de sistemas concorrentes, pois permite que múltiplos threads ou processos trabalhem juntos sem interferir uns nos outros. Contudo, deve-se ter cuidado ao projetar e implementar seções críticas, pois a sincronização incorreta pode levar a condições de corrida e deadlocks.
Introdução
Quando mais de um processo tenta acessar o mesmo segmento de código, esse segmento é conhecido como seção crítica. A seção crítica contém variáveis compartilhadas ou recursos que precisam ser sincronizados para manter a consistência das variáveis de dados.
Em termos simples, uma seção crítica é um grupo de instruções/declarações ou regiões de código que precisam ser executadas atomicamente, como acessar um recurso (arquivo, porta de entrada ou saída, dados globais, etc.). Um thread tenta alterar o valor dos dados compartilhados ao mesmo tempo que outro thread tenta ler o valor (ou seja, corrida de dados entre threads), o resultado é imprevisível. O acesso a tais variáveis compartilhadas (memória compartilhada, arquivos compartilhados, porta compartilhada, etc.) deve ser sincronizado.
Poucas linguagens de programação possuem suporte integrado para sincronização. É fundamental compreender a importância das condições de corrida ao escrever a programação no modo kernel (um driver de dispositivo, thread do kernel, etc.), uma vez que o programador pode acessar e modificar diretamente as estruturas de dados do kernel.
Embora existam algumas propriedades que devem ser seguidas se houver algum código na seção crítica:
- Exclusão Mútua: Se o processo Pi estiver sendo executado em sua seção crítica, nenhum outro processo poderá estar sendo executado em suas seções críticas.
- Progresso: Se nenhum processo estiver executando em sua seção crítica e alguns processos desejarem entrar em suas seções críticas, então apenas aqueles processos que não estão executando em suas seções restantes poderão participar na decisão de qual entrará em seguida em sua seção crítica, e esta seleção não pode ser adiada indefinidamente.
- Espera Limitada: Existe um limite no número de vezes que outros processos podem entrar em suas seções críticas após um processo ter feito uma solicitação para entrar em sua seção crítica e antes que essa solicitação seja atendida.
Duas abordagens gerais são usadas para lidar com seções críticas:
- Kernels preemptivos: Um kernel preemptivo permite que um processo seja preemptado enquanto estiver sendo executado no modo kernel.
- Kernels não preemptivos: Um kernel não preemptivo não permite que um processo em execução no modo kernel seja preemptado; um processo no modo kernel será executado até que exista no modo kernel, bloqueie ou ceda voluntariamente o controle da CPU. Um kernel não preemptivo é essencialmente livre de condições de corrida nas estruturas de dados do kernel, pois somente um processo está ativo no kernel por vez.
Problema
O uso de seções críticas em um programa pode causar vários problemas, inclusive:
Deadlock: Quando dois ou mais threads ou processos esperam um pelo outro para liberar uma seção crítica, isso pode resultar em uma situação de deadlock na qual nenhum dos threads ou processos pode se mover. Os deadlocks podem ser difíceis de detectar e resolver e podem ter um impacto significativo no desempenho e na confiabilidade de um programa.
Starvation: Quando um thread ou processo é repetidamente impedido de entrar em uma seção crítica, isso pode resultar em starvation, em que o thread ou processo não consegue progredir. Isso pode acontecer se a seção crítica for mantida por um período de tempo excepcionalmente longo ou se um thread ou processo de alta prioridade sempre tiver prioridade ao entrar na seção crítica.
Sobrecarga: Ao usar seções críticas, os threads ou processos devem adquirir e liberar bloqueios ou semáforos, o que pode consumir tempo e recursos. Isso pode reduzir o desempenho geral do programa.
Alguns livros de referência que abordam a seção crítica e tópicos relacionados são:
- “Operating System Concepts”, de Silberschatz, Galvin e Gagne.
- “Modern Operating Systems”, de Andrew S. Tanenbaum.
- “Advanced Programming in the UNIX Environment”, de W. Richard Stevens e Stephen A. Rago.
- “The Art of Multiprocessor Programming”, de Maurice Herlihy e Nir Shavit.
- “Concurrent Programming in Java: Design Principles and Patterns”, de Doug Lea.
Exclusão Mútua
A exclusão mútua é uma propriedade da sincronização de processos que afirma que “não podem existir dois processos na seção crítica em um determinado momento”. O termo foi cunhado pela primeira vez por Dijkstra. Qualquer técnica de sincronização de processos que esteja sendo usada deve satisfazer a propriedade de exclusão mútua, sem a qual não seria possível se livrar de uma condição de corrida.
A necessidade de exclusão mútua vem com a simultaneidade. Há vários tipos de execução simultânea:
- Manipuladores de interrupções
- Processos/threads intercalados e programados de forma preemptiva
- Clusters de multiprocessadores, com memória compartilhada
- Sistemas distribuídos
Os métodos de exclusão mútua são usados na programação concorrente para evitar o uso simultâneo de um recurso comum, como uma variável global, por partes do código do computador chamadas seções críticas.
O requisito da exclusão mútua é que, quando o processo P1 estiver acessando um recurso compartilhado R1, outro processo não poderá acessar o recurso R1 até que o processo P1 tenha concluído sua operação com o recurso R1.
Exemplos de tais recursos incluem arquivos, dispositivos de E/S, como impressoras, e estruturas de dados compartilhadas.
Condições
De acordo com os quatro critérios seguintes, a exclusão mútua é aplicável:
- Ao utilizar recursos partilhados, é importante garantir a exclusão mútua entre vários processos. Não pode haver dois processos rodando simultaneamente em qualquer uma de suas seções críticas.
- Não é aconselhável fazer suposições sobre as velocidades relativas dos processos instáveis.
- Para acessar a seção crítica, um processo que está fora dela não deve obstruir outro processo.
- Sua seção crítica deve ser acessível por múltiplos processos em um período de tempo finito; vários processos nunca devem ficar esperando em um loop infinito.
Abordagens de implementação
Método de software: Deixar a responsabilidade para os próprios processos. Esses métodos costumam ser muito propensos a erros e acarretam altos custos indiretos.
Método de hardware: Instruções de máquina para fins especiais são usadas para acessar recursos compartilhados. Esse método é mais rápido, mas não oferece uma solução completa. As soluções de hardware não podem garantir a ausência de deadlock e starvation.
Método de linguagem de programação: Fornece suporte por meio do sistema operacional ou da linguagem de programação.
Requisitos:
- A qualquer momento, apenas um processo pode entrar em sua seção crítica.
- A solução é implementada puramente em software em uma máquina.
- Um processo permanece dentro de sua seção crítica apenas por um tempo limitado.
- Nenhuma suposição pode ser feita sobre as velocidades relativas de processos assíncronos simultâneos.
- Um processo não pode impedir que qualquer outro processo entre em uma seção crítica.
- Um processo não pode ser adiado indefinidamente para entrar em sua seção crítica.
Quando usar?
Uma maneira fácil de visualizar o significado da exclusão mútua é imaginar uma lista vinculada de vários itens, com o quarto e o quinto itens que precisam ser removidos. Ao alterar a próxima referência do nó anterior para apontar para o nó seguinte, o nó que fica entre os outros dois nós é excluído.
Simplificando, sempre que o nó “i” quiser ser removido, a referência subsequente do nó “com - 1″ é alterada para apontar para o nó “ith + 1” naquele momento. Dois nós distintos podem ser removidos por dois threads ao mesmo tempo quando uma lista vinculada compartilhada estiver sendo usada por muitos threads. Isso ocorre quando o primeiro thread modifica a próxima referência do nó “ith - 1”, apontando para o nó “ith + 1”, e o segundo thread modifica a próxima referência do nó “ith”, apontando para o nó “ith + 2”. Embora ambos os nós tenham sido removidos, o estado necessário da lista vinculada ainda não foi alcançado porque o nó “i + 1” ainda existe na lista porque a próxima referência do nó “ith - 1” ainda aponta para ele.
Agora, essa situação é chamada de condição de corrida. As condições de corrida podem ser evitadas por meio de exclusão mútua, de modo que as atualizações ao mesmo tempo não possam ocorrer na mesma parte da lista.
Exemplo:
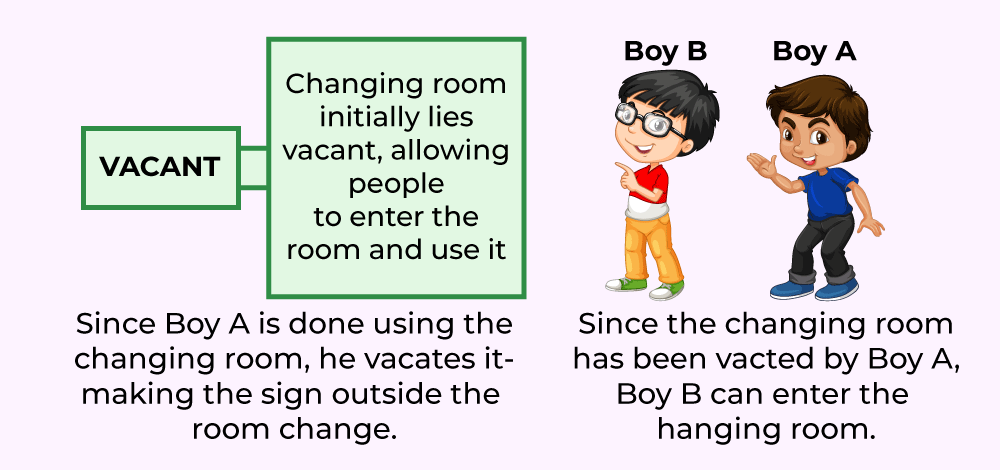
Na seção de roupas de um supermercado, duas pessoas estão comprando roupas.

Fonte: GeeksForGeeks
O garoto A decide comprar algumas roupas e se dirige ao vestiário para experimentá-las. Agora, enquanto o menino A está no vestiário, há uma placa de “ocupado”, indicando que ninguém mais pode entrar. A garota B também precisa usar o vestiário, portanto, ela tem de esperar até que o garoto A termine de usar o vestiário.

Fonte: GeeksForGeeks
Quando o garoto A sai do vestiário, o sinal muda de “ocupado” para “vago”, indicando que outra pessoa pode usá-lo. Assim, a garota B passa a usar o vestiário, enquanto a placa mostra “ocupado” novamente.
O vestiário nada mais é do que a seção crítica, o menino A e a menina B são dois processos diferentes, enquanto a placa fora do vestiário indica o mecanismo de sincronização de processos que está sendo usado.
Fonte: GeeksForGeeks
Progresso de um Processo
A exclusão mútua, por si só, não pode garantir a execução simultânea de processos sem problemas - uma segunda condição conhecida como progresso é necessária para garantir que não ocorra nenhum deadlock durante essa execução.
Uma definição formal de progresso é apresentada por Galvin como:
“Se nenhum processo estiver sendo executado em sua seção crítica e alguns processos desejarem entrar em suas seções críticas, somente os processos que não estiverem sendo executados em sua seção restante poderão participar da decisão de qual entrará em sua seção crítica em seguida, e essa seleção não poderá ser adiada indefinidamente.”
Exemplo:
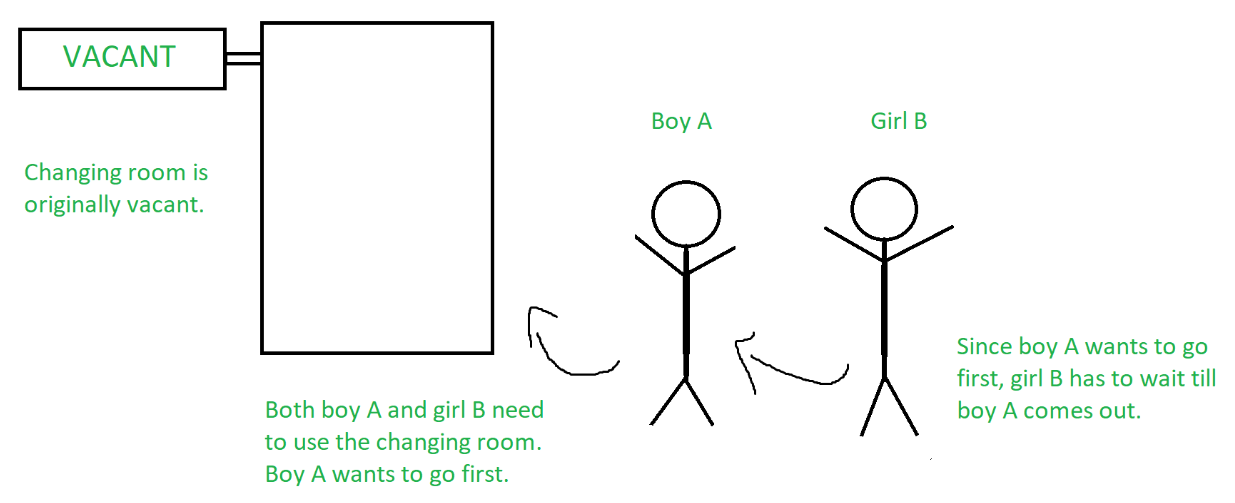
São muitas coisas para assimilar de uma só vez, então vamos usar um exemplo para ver como nossa afirmação é válida. Suponha que, na seção de roupas de uma loja de departamentos, um menino A e uma menina B queiram usar o vestiário.
Fonte: GeeksForGeeks
O garoto A decide usar o vestiário primeiro, mas não consegue decidir quantas roupas levará com ele. Como resultado, embora o vestiário esteja vazio, a garota B (que já decidiu quantas roupas vai experimentar) não pode entrar no vestiário porque está obstruída pelo garoto A.
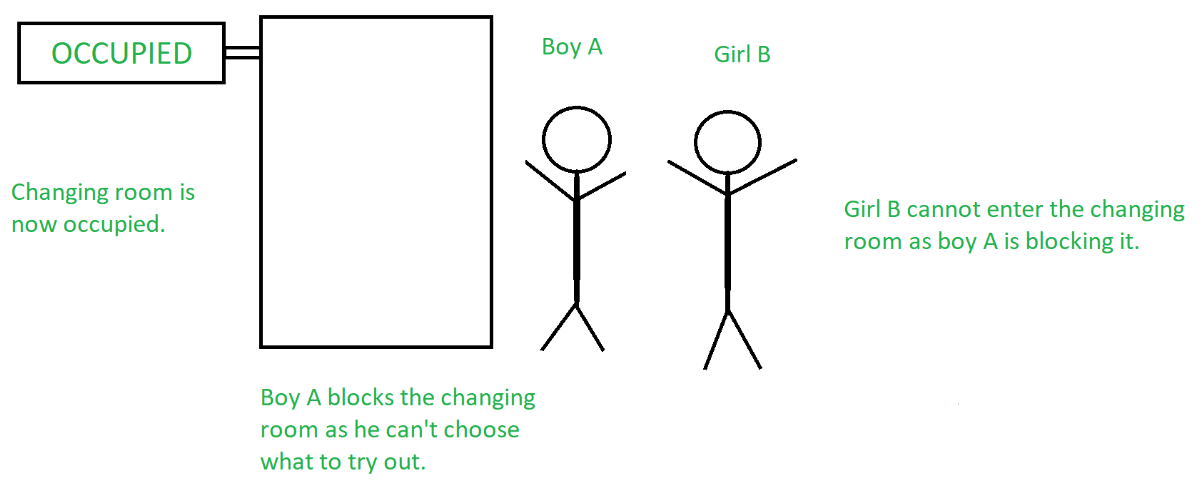
Fonte: GeeksForGeeks
Em outras palavras, o menino A impede que a menina B use o vestiário, mesmo que ele não precise usá-lo. É isso que o conceito de progresso foi criado para evitar.
De acordo com a definição principal de progresso, os únicos processos que podem participar da tomada de decisão sobre quem pode entrar na seção crítica são aqueles que estão prestes a entrar na seção crítica ou que estão executando algum código antes de entrar na seção crítica. Os processos que estão na seção de lembrete, que é a seção que sucede a seção crítica, não têm permissão para participar desse processo de tomada de decisão.
A principal função do progresso é garantir que um processo esteja sendo executado na seção crítica em qualquer momento (de modo que algum trabalho esteja sempre sendo feito pelo processador). Essa decisão não pode ser “adiada indefinidamente” - em outras palavras, deve levar um tempo limitado para selecionar qual processo deve ter permissão para entrar na seção crítica. Se essa decisão não puder ser tomada em um tempo finito, isso levará a um deadlock.
Problemas de sincronização de thread
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
pthread_t tid[2];
int counter;
void* trythis(void* arg)
{
unsigned long i = 0;
counter += 1;
printf("\n Job %d has started\n", counter);
for (i = 0; i < (0xFFFFFFFF); i++)
;
printf("\n Job %d has finished\n", counter);
return NULL;
}
int main(void)
{
int i = 0;
int error;
while (i < 2) {
error = pthread_create(&(tid[i]), NULL, &trythis, NULL);
if (error != 0)
printf("\nThread can't be created : [%s]", strerror(error));
i++;
}
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
return 0;
}
Resultado:
Job 1 has started
Job 2 has started
Job 2 has finished
Job 2 has finished
Problema: nos dois últimos registros, é possível ver que o registro “Job 2 has finished” é repetido duas vezes, enquanto nenhum registro para “Job 1 has finished” é visto.
Observando atentamente e visualizando a execução do código, podemos ver que :
- O registro “Job 2 has started” é impresso logo após “Job 1 has Started”, portanto, pode-se concluir facilmente que, enquanto o thread 1 estava sendo processado, o agendador programou o thread 2.
- Se considerarmos a suposição acima verdadeira, o valor da variável ‘counter’ foi incrementado novamente antes do término do trabalho 1.
- Assim, quando o trabalho 1 realmente foi concluído, o valor errado do contador produziu o registro “Job 2 has finished” seguido por “Job 2 has finished” para o trabalho 2 real ou vice-versa, pois isso depende do agendador.
- Portanto, vemos que o problema não é o registro repetitivo, mas o valor errado da variável “counter”.
- O problema real era o uso da variável ‘counter’ por um segundo thread quando o primeiro thread estava usando ou prestes a usá-la.
- Em outras palavras, podemos dizer que a falta de sincronização entre os threads durante o uso do recurso compartilhado “counter” causou os problemas ou, em uma palavra, podemos dizer que esse problema ocorreu devido a um “problema de sincronização” entre dois threads.
Mutex
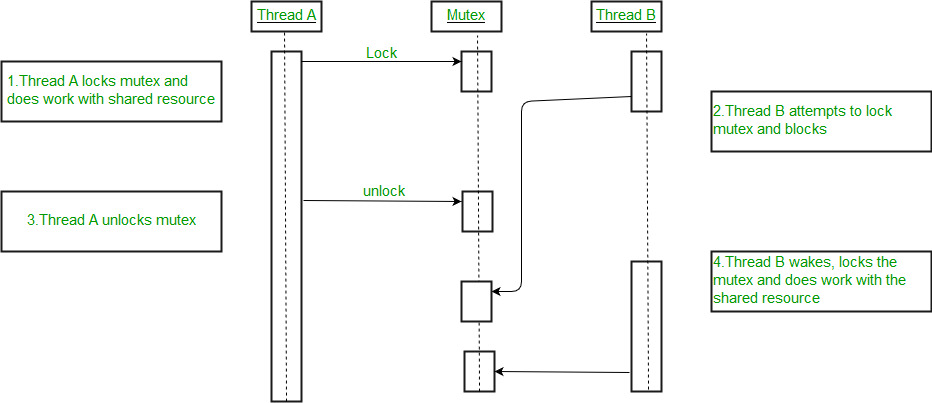
- Um Mutex é um bloqueio que definimos antes de usar um recurso compartilhado e liberamos depois de usá-lo.
- Quando o bloqueio é definido, nenhum outro thread pode acessar a região bloqueada do código.
- Portanto, vemos que, mesmo que o thread 2 seja programado enquanto o thread 1 não tiver terminado de acessar o recurso compartilhado e o código estiver bloqueado pelo thread 1 usando mutexes, o thread 2 não poderá acessar essa região do código.
- Portanto, isso garante o acesso sincronizado de recursos compartilhados no código.
Fonte: GeeksForGeeks
An example to show how mutexes are used for thread synchronization
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
pthread_t tid[2];
int counter;
pthread_mutex_t lock;
void* trythis(void* arg)
{
pthread_mutex_lock(&lock);
unsigned long i = 0;
counter += 1;
printf("\n Job %d has started\n", counter);
for (i = 0; i < (0xFFFFFFFF); i++)
;
printf("\n Job %d has finished\n", counter);
pthread_mutex_unlock(&lock);
return NULL;
}
int main(void)
{
int i = 0;
int error;
if (pthread_mutex_init(&lock, NULL) != 0) {
printf("\n mutex init has failed\n");
return 1;
}
while (i < 2) {
error = pthread_create(&(tid[i]),
NULL,
&trythis, NULL);
if (error != 0)
printf("\nThread can't be created :[%s]",
strerror(error));
i++;
}
pthread_join(tid[0], NULL);
pthread_join(tid[1], NULL);
pthread_mutex_destroy(&lock);
return 0;
}
Resultado:
Job 1 has started
Job 1 has finished
Job 2 has started
Job 2 has finished
- Um mutex é inicializado no início da função principal.
- O mesmo mutex é bloqueado na função ’trythis()’ enquanto usa o recurso compartilhado ‘counter’.
- No final da função ’trythis()’, o mesmo mutex é desbloqueado.
- No final da função principal, quando ambos os threads terminam, o mutex é destruído.
Portanto, desta vez, os registros de início e término de ambos os trabalhos estão presentes. Portanto, a sincronização de thread ocorreu com o uso do Mutex.
Mutex vs Semaphore
Mutex
Mutex é um tipo específico de semáforo binário usado para fornecer um mecanismo de bloqueio. Significa Objeto de Exclusão Mútua. O Mutex é usado principalmente para fornecer exclusão mútua a uma parte específica do código, de modo que o processo possa executar e trabalhar com uma seção específica do código em um determinado momento.
O Mutex usa um mecanismo de herança de prioridade para evitar problemas de inversão de prioridade. O mecanismo de herança de prioridade mantém os processos de prioridade mais alta no estado bloqueado pelo menor tempo possível. Entretanto, isso não pode evitar o problema de inversão de prioridade, mas pode reduzir seu efeito até certo ponto.
Desvantagens:
- Se, depois de entrar na seção crítica, o thread dormir ou for impedido por um processo de alta prioridade, nenhum outro thread poderá entrar na seção crítica. Isso pode levar à starvation.
- Quando o thread anterior deixa a seção crítica, depois disso somente outros processos podem entrar nela, não há outro mecanismo para bloquear ou desbloquear a seção crítica.
- A implementação do mutex pode levar a uma espera prolongada que leva ao desperdício do ciclo da CPU.
Semáforo
Um semáforo é uma variável de número inteiro não negativo que é compartilhada entre vários threads. O semáforo funciona com base no mecanismo de sinalização, no qual um thread pode ser sinalizado por outro thread. O semáforo usa duas operações atômicas para sincronização de processos:
- Wait (P)
- Signal (V)
Vantagens:
- Vários threads podem acessar a seção crítica ao mesmo tempo.
- Os semáforos são independentes da máquina.
- Somente um processo acessará a seção crítica por vez, mas vários threads são permitidos.
- Os semáforos são independentes da máquina, portanto, devem ser executados no microkernel.
- Gerenciamento flexível de recursos.
Desvantagens:
- Ele tem inversão de prioridade.
- A operação do semáforo (Wait, Signal) deve ser implementada da maneira correta para evitar deadlock.
- Isso leva a uma perda de modularidade, portanto, os semáforos não podem ser usados em sistemas de grande escala.
- O semáforo é propenso a erros de programação e isso pode levar a um deadlock ou à violação da propriedade de exclusão mútua.
- O sistema operacional precisa rastrear todas as chamadas para operações de espera e sinal.
| Mutex | Semáforo |
|---|---|
| Um mutex é um objeto. | Um semáforo é um número inteiro. |
| Mutex funciona no mecanismo de bloqueio. | Semáforo usa mecanismo de sinalização |
| Operações em mutex: | Operação em semáforo: |
| Bloquear | Esperar |
| Desbloquear | Sinal |
| Mutex não possui subtipos. | O semáforo é de dois tipos: |
| – | Contando Semáforo |
| – | Semáforo Binário |
| Um mutex só pode ser modificado pelo processo que está solicitando ou liberando um recurso. | O semáforo funciona com duas operações atômicas (Espera, Sinal) que podem modificá-lo. |
| Se o mutex estiver bloqueado, o processo precisará aguardar na fila de processos e o mutex só poderá ser acessado quando o bloqueio for liberado. | Se o processo precisar de um recurso e nenhum recurso estiver livre. Assim, o processo precisa realizar uma operação de espera até que o valor do semáforo seja maior que zero. |
Atomic Operation
Quando uma operação atômica é executada em um objeto por um thread específico, nenhum outro thread pode ler ou modificar o objeto enquanto a operação atômica estiver em andamento. Isso significa que outros threads só verão o objeto antes ou depois da operação - nenhum estado intermediário.
Vamos dar uma olhada em alguns códigos para entender isso.
#include <iostream>
#include <thread>
int main()
{
int sum = 0;
auto f = [&sum](){
for(int i = 0; i < 1000000; i++)
{
sum += 1;
}
};
std::thread t1(f);
std::thread t2(f);
t1.join();
t2.join();
std::cout << sum << std::endl;
return 0;
}
Nesse código, estamos incrementando a soma em dois threads sem nenhuma sincronização entre eles. Poderíamos supor, ingenuamente, que sempre teríamos 2000000 como resultado, porque os dois threads estão incrementando 1000000 vezes cada um. Se compilarmos e executarmos esse código, descobriremos que isso não é verdade.
Resultado:
$ g++ --version
g++ (GCC) 11.4.0
$ g++ -dumpmachine
x86_64-pc-cygwin
$ g++ nonatomic.cpp -o app
$ ./app
1508328
$ ./app
1096773
$ ./app
1303703
Cada execução imprime uma saída diferente. Isso é obviamente indesejável, mas o que está acontecendo exatamente aqui?
Quando a soma é incrementada por um thread, o valor precisa ser lido da memória, modificado (incrementado) e gravado de volta na memória. Em outras palavras, é uma operação de leitura-modificação-gravação.
Sem qualquer sincronização, os dois threads leriam a soma da memória como 0, incrementariam, e gravariam 1 na memória. Isso significa que qualquer thread que gravar primeiro terá seu resultado pisoteado pelo outro thread.
Isso é conhecido como corrida de dados, que é um comportamento indefinido. Tecnicamente, tudo pode acontecer, incluindo o seu programa se tornar senciente e colonizar a raça humana. Mas na realidade, como visto no nosso exemplo, podemos perder o resultado de alguns dos incrementos.
É importante observar que em x86, leituras e gravações são atômicas para tipos integrados. Este pode não ser o caso em outras plataformas, portanto, fazer leituras e gravações não atômicas na mesma variável a partir de threads separados significa que você realmente poderá ver qualquer coisa em sua saída. Comportamento indefinido realmente significa comportamento indefinido!
No entanto, você pode estar se perguntando: se as leituras e gravações em x86 são atômicas, por que a saída ainda é inconsistente? Isso ocorre porque a operação de incremento (leitura-modificação-gravação) como um todo não é atômica. Isso significa que outro thread pode obter uma palavra entre a leitura e a gravação atômicas.
Primeiramente, podemos garantir a atomicidade declarando sum como uma variável atômica. Podemos então dividir o incremento em uma leitura atômica, seguida por uma gravação atômica como tal
#include <iostream>
#include <thread>
#include <atomic>
int main()
{
std::atomic<int> sum(0);
auto f = [&sum](){
for(int i = 0; i < 1000000; i++)
{
sum = sum + 1;
}
};
std::thread t1(f);
std::thread t2(f);
t1.join();
t2.join();
std::cout << sum << std::endl;
return 0;
}
Se compilarmos e executarmos o código, conforme esperado, ainda obteremos resultados inconsistentes.
Em um nível baixo, o seguinte pode acontecer em uma máquina x86:
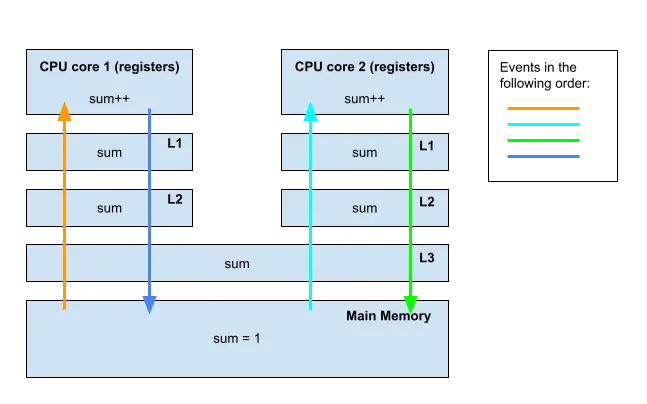
Fonte: Medium
- O cache do núcleo 1 busca atomicamente a soma da memória (soma == 0). O núcleo 1 incrementa para 1.
- O cache do Core 2 busca atomicamente a soma da memória (soma == 0). O núcleo 2 incrementa para 1.
- O Core 2 grava 1 de volta em seu cache, que é transferido para a memória (soma == 1).
- O núcleo 1 grava 1 de volta em seu cache, que também se propagará para a memória, pisando no valor gravado pelo núcleo 2 (soma == 1). Novamente, podemos perder o resultado de um dos incrementos.
Para garantir resultados consistentes, queremos garantir que a operação de incremento como um todo seja atômica. Podemos atualizar nosso código como tal para conseguir isso.
#include <iostream>
#include <thread>
#include <atomic>
int main()
{
std::atomic<int> sum(0);
auto f = [&sum](){
for(int i = 0; i < 1000000; i++)
{
sum++; // Same as sum+=1;
}
};
std::thread t1(f);
std::thread t2(f);
t1.join();
t2.join();
std::cout << sum << std::endl;
return 0;
}
Isso ocorre porque std::atomic sobrecarrega o operador+= e o operador++ que incrementa atomicamente o valor. O mesmo resultado poderia ser alcançado com fetch_add(). Ao garantir que a operação de leitura-modificação-gravação seja feita atomicamente, alcançamos o comportamento desejado.
Voltando ao nível inferior:
- O Core 1 adquire acesso exclusivo (hardware) à soma.
- O cache do núcleo 1 busca a soma da memória (soma == 0).
- O núcleo 1 então incrementa o valor para 1 e grava em seu cache, que desce para a memória principal e libera o acesso exclusivo.
- O Core 2 fará o mesmo processo e incrementará a soma para 2.
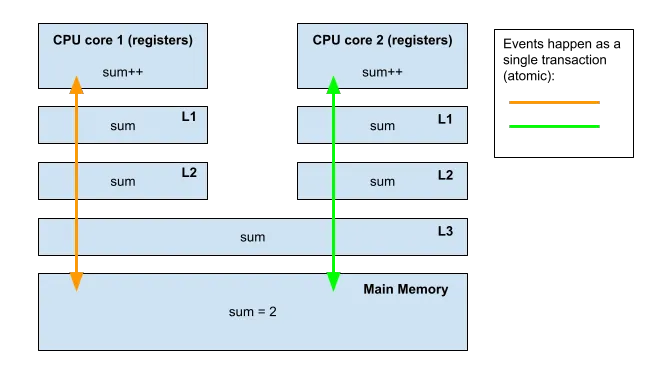
Fonte: Medium
Estudos Futuros
- Concurrency Memory Models
- Memory Barriers
- Futures
- Fibers
- Coroutines
- Non-blocking algorithm (Lock-free)
Thread Sanitizer
O Thread Sanitizer, ou TSan, é uma ferramenta que nos permite depurar corridas de dados quando vários threads tentam acessar a mesma área de memória de forma não atômica e com pelo menos uma operação de gravação em um desses threads.
Essas corridas de dados são realmente difíceis de depurar porque são extremamente imprevisíveis, às vezes funcionam e às vezes não, você nunca sabe qual thread chegou lá primeiro.
As corridas de dados são um tipo particularmente desagradável de bugs de threading. Elas são difíceis de encontrar e reproduzir - você pode não observar um bug durante todo o ciclo de testes e só o verá na produção como falhas raras e inexplicáveis.